
The Missing Message Mystery


This is the story of our experience looking into a bug that caused our Optimistic Ethereum testnet deployment to stop accepting new L1 ⇒ L2 deposits for a period of several days in the early days of June 2021. For some context, L1 ⇒ L2 deposits take assets sitting on an L1 chain (like Ethereum) and move them into an L2 chain (like Optimistic Ethereum). During the incident, the testnet deployment was unable to correctly credit deposits. I found this story fascinating because we were able to create a reasonable fix for the issue without understanding the exact source of the bug. It’s one of those stories that highlights the messy reality of building software for humans. I’ll also be interspersing this post with some of the engineering lessons we took away from the incident. Enjoy!
Noticing the symptoms
We first became aware of an issue with Kovan deposits after several users reported the problem to us directly (a reminder that we need to improve our automatic alerting for these sorts of problems). The general symptoms reported were that users were able to start deposits by sending transactions on L1 but would never receive any funds on L2. Obviously this was pretty problematic because it prevented users from moving assets into L2. This definitely had to be fixed as quickly as possible.
Engineering Lesson #1: user reports are a last line of defense
User reports should be a last line of defense when discovering issues. If you’re finding issues because of user reports then you probably don’t have sufficient alerting in place. In this specific case we should’ve been regularly submitting deposit transactions and monitoring those transactions for failures.
Starting the debugging process
We started our debugging session by making a small list of the different pieces of the software that could potentially be causing the problem. Based on user reports, we knew the following:
- Deposits could be correctly initiated on L1
- Deposits were NOT correctly being reflected on L2
Point (1) meant that the bug likely wasn’t coming from our smart contracts (the deposit transactions would probably be reverting if it was an issue in the smart contracts). Luckily our software stack is relatively simple and there aren’t many places for a bug to hide. If the issue wasn’t in the contracts, then it was either in the L2 geth node OR in the process that carries transactions over to L2 geth (a tool known as data transport layer or DTL for short; it’s a terribly vague name and we’re accepting suggestions for alternatives 😂).
The DTL is a minimal piece of software that doesn’t often see failures like this. We made a few deposits of our own and found that the DTL was correctly discovering and indexing these deposits, so our suspicion turned to L2 geth. A quick skim through the logs didn’t reveal much other than the fact that our new deposit transactions were clearly not being executed on L2.
Fortunately, our luck turned when we found the following log lines:
Syncing enqueue transactions range start=2500 end=3545
...
Syncing enqueue transactions range start=2500 end=3546
...
Syncing enqueue transactions range start=2500 end=3547
These logs are emitted when L2 geth tries to execute a series of L1 ⇒ L2 deposit transactions. We’d expect the start value to increase over time because L2 geth should be executing one transaction and moving on to the next. The fact that the start value wasn't changing suggested that L2 geth was somehow getting stuck when trying to execute deposit 2500. Now we just had to find out what was going on with deposit 2500.
Checking the DTL
The easiest way to figure out what was going on was to check the data transport layer to see what was getting sent over to L2 geth. The DTL has a nice API that we can manually query to see what’s being sent over to the sequencer. So we sent the following query:
GET <https://url.of.dtl/enqueue/index/2500>
What did we get back? null. Apparently the DTL just didn't have any record of this deposit.
So what about deposit 2501?
GET <https://url.of.dtl/enqueue/index/2501>
Not null! Yep, the DTL had a record for that. And it had a record for every other deposit after that. This was clearly the source of the initial issue. The DTL didn't have a record of deposit 2500 so L2 geth wasn't able to progress beyond deposit 2500 but new deposits were still being accepted. Hmm...
Finding the root cause
The bizarre nature of this bug suggested that it might be non-deterministic. I mean, why would just deposit 2500 be missing? Sure enough, a new DTL synced from scratch picked up the deposit just fine. This meant we could get the system back online by resetting the production DTL, but we still didn't understand exactly why this had happened in the first place. Aiming to avoid similar problems in the future, we set out to find a root cause.
Lucky for us, the DTL is a relatively simple piece of software — it doesn’t do very much. It’s basically just a loop that:
- Looks up the last L1 block it’s in sync with
- Finds the next L1 block to sync to
- Finds, parses, and stores events within that block range
- Updates the last L1 block it’s in sync with
As a result, there just aren’t many things that can cause it to break like this. Nothing obvious stood out to us, so we ended up having to do a good bit of digging. We came up with three potential sources of the bug in order of decreasing likelihood.
Option 1: Maybe Kovan reorg’d
Our first intuition was that maybe Kovan had experienced a large block reorganization. When large reorgs happen, nodes may temporarily see outdated views of the network. The DTL on Kovan was configured to wait for 12 confirmations (blocks) before accepting a transaction. If this were the root cause then we’d expect to see some sort of reorg of more than 12 blocks.
A quick look at Etherscan’s reorg list and we were back to square one. At the time of the incident, no reorgs had occurred for almost a month. Unless Etherscan was experiencing a large localized outage and falling out of sync with the rest of Kovan, it’s unlikely that there was any sort of 12+ block reorg that went unnoticed. On to the next one.
Option 2: Maybe we accidentally skipped a block
If it wasn’t a reorg, then maybe our software really did just accidentally skip a block during the sync process. Although this seemed pretty unlikely, we needed to make sure that this wasn’t the source of the issue.
To figure out whether we’d skipped a block or not, we had to find a specific log line that would tell us if we’d scanned the L1 block that contained the deposit. In order to do that, we first needed to find the block in which the event was emitted. So we went back to Etherscan to search for the deposit:
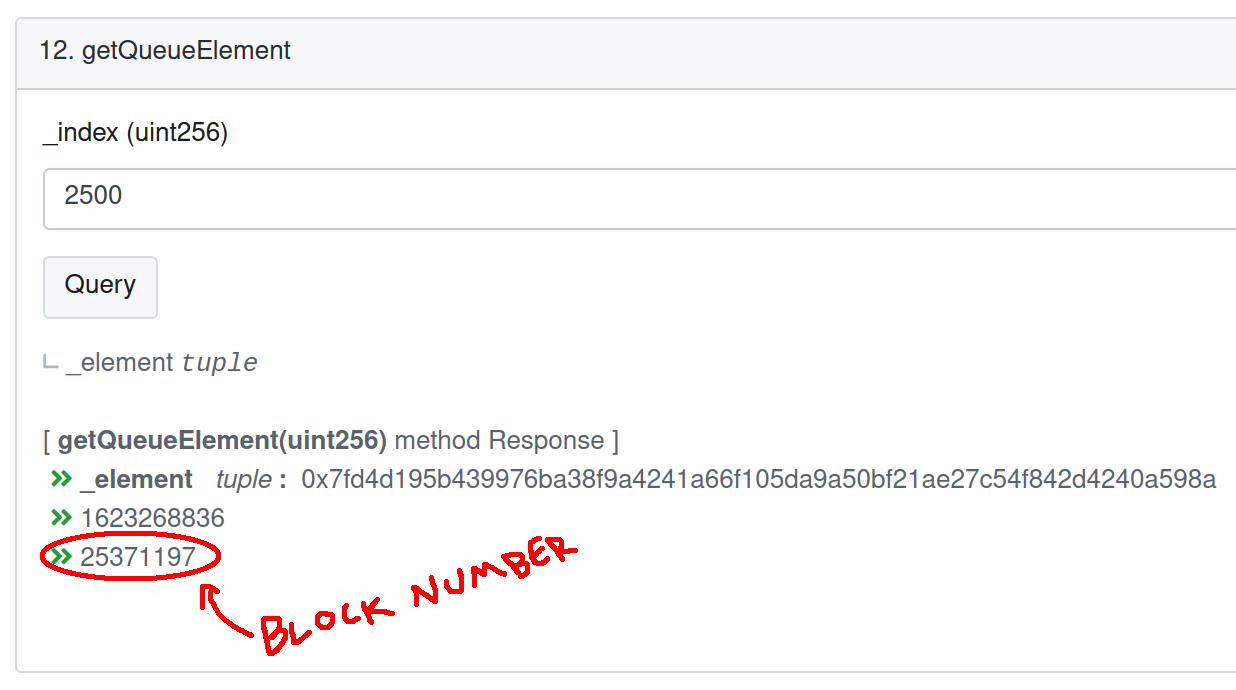
The return value here is a struct of the form:
struct QueueElement {
bytes32 transactionHash;
uint40 timestamp;
uint40 blockNumber;
}
Where the timestamp and blockNumber here are the timestamp and block number of the block in which this deposit was submitted. We had what we came for: this deposit was submitted in block 25371197. Now we just had to take a look through the DTL logs to (hopefully) find a log covering the block in question. Sure enough:

The targetL1Block in this log line matches the L1 block we were looking for. We definitely attempted to sync the block that contained the deposit. So why didn't we see anything?
Option 3: Maybe Infura broke
Our investigation into the DTL logs made it clear that the deposit should’ve been detected by the DTL but wasn’t. Additionally, the DTL didn’t throw any errors when it was syncing this block. We just didn’t find any events.
Relatively confident in our DTL code, we started to look for potential reasons to blame someone other than ourselves (because it’s easier that way). We found that Infura was returning various 504 errors at around the same time that this error was triggered:

Interesting? Yes. Proof of a problem with Infura? Not so much. Maybe something went wrong at Infura on June 9th. Or maybe not. Who knows. Unfortunately, we did not store a record of our RPC requests and were therefore not able to debug this issue any further with logs alone.
Engineering Lesson #2: keep a record of your RPC requests.
If an Ethereum node is critical to your system, consider keeping a record of all RPC requests made to the node. Logs can always be deleted after some reasonable period of time to keep storage costs low.
Engineering Lesson #3: Infura is not consensus.
Consider sending requests to multiple nodes or node providers simultaneously to cross-check the validity of incoming results. Consider hosting one or more of these nodes yourself. You absolutely should not rely on the assumption that your node provider will always return correct results. Trust, but verify.
Solution: Learn, adapt, and move on.
We were stuck with a relatively unsatisfying conclusion: either Infura broke or there was a bug in our system that we couldn’t figure out. We were also under a bit of pressure because people rely on our Kovan testnet, and deposits into the system were still completely borked. We knew we could resync the DTL to get the system back up but without a root cause we were probably just setting ourselves up to face the same issue in another day or two.
After some discussion, a compromise was drawn:
- Resync the DTL to get the system back up.
- Add some more logic to the DTL so it can recover from missing events.
- Add a log line whenever this recovery logic is triggered so we can debug further in the future.
This strategy made the best of the situation. The DTL’s new recovery logic shielded us from the worst effects of the underlying problem. If the bug ever reared its head again we’d get a convenient log line instead of a halted system. Win-win.
Engineering Lesson #4: root cause isn’t everything.
Sometimes it’s possible (or even preferable) to mitigate an issue before you fully understand it. You should still monitor for future of occurrences of the issue. Consider brainstorming other effects that the unknown bug may trigger on your system.
Conclusion
And such it was that we could effectively mitigate a bug without understanding its root cause. Our patch has successfully recovered from this error on multiple occasions since the original incident. At the time of writing this post, we still haven’t figured out the root cause of this issue — we have too many other things to work on and our recovery logic is doing a perfectly fine job at dealing with this in the meantime (yay, fault tolerance!).
I found this saga so interesting because it highlighted some of the dirtier aspects of software engineering. The process of building and maintaining software is never as straightforward as we’d all like it to be. Practical concerns can often come at the expense of doing things the “ideal” way. At the end of the day, good software engineering is more like a rough science than pure mathematics. You will need to deal with the messy situations that arise when people are building software for other people. All you can do is make the best of it: learn, adapt, and move on.
We’re hiring to build the future of Ethereum. If you liked what you read here, check out our job listings. Maybe you’ll find your next home. 💖